点击论坛跳转到相应位置
视言碰撞:语言模型与视觉生态协同
论坛简介
随着语言与视觉大模型的迅猛发展,语言模型与视觉生态紧密地交互,诞生出了空前的探索机遇,也引领了当下研究的前沿与潮流。本论坛从语言模态和视觉模态的碰撞出发,重点探讨语言模型对于视觉生成、感知、理解乃至交互多个层面的协同与促进作用,希望对这一领域的研究和发展做出积极的贡献。具体地,本次论坛特邀讲者的报告内容主要涵盖(1)如何修正语言模型获取高质量的图像生成及2D/3D图像生成模型;(2)如何利用语言模型进行视觉任务的调度;(3)如何掌控3D视觉交互与控制。我们期待在本论坛中与各位研究者和从业者共同探讨,推动这一领域的发展,创造出更多创新的应用,激发出更多的创造潜力。论坛预计200人。
论坛主席

个人简介:
程明明,南开大学杰出教授,主持承担了国家杰出青年科学基金、优秀青年科学基金项目、科技部重大项目课题等。他的主要研究方向是计算机视觉和计算机图形学,在SCI一区/CCF A类刊物上发表学术论文100余篇(含IEEE TPAMI论文30余篇),h-index为80,论文谷歌引用4万余次,单篇最高引用4700余次,多次入选全球高被引科学家和中国高被引学者。技术成果被应用于华为、国家减灾中心等多个单位的旗舰产品。获得教育部自然科学一等奖2项、其他省部级科技奖2项。培养的3名博士生获得省部级优秀博士论文奖。现担任中国图象图形学学会副秘书长、天津市人工智能学会副理事长和顶级期刊IEEE TPAMI, IEEE TIP和《中国科学:信息科学》编委。

个人简介:
王亚星,南开大学副教授,博士生导师,入选海外高层次人才引进计划青年项目,入选南开“百名青年学科带头人培养计划”。西班牙巴塞罗那自治大学博士,曾在西班牙巴塞罗那自治大学从事博士后研究。研究方向为扩散模型、生成对抗网络、图像到图像翻译、迁移学习。在TPAMI,IJCV,CVPR,NeurIPS等期刊会议发表论文30余篇,谷歌学术引用2000余次。现担任Computers, Materials & Continua期刊编委,ECCV Workshop 组织者,在国际顶级期刊和会议TPAMI、NeurIPS、CVPR、ICCV等多次担任期刊和会议审稿人。多模态语言翻译国际竞赛 (WMT16 Multimodal Machine Translation challenge) 中 荣获第一名、2022年粤港澳大湾区(黄埔)国际算法算例大赛(遥感目标检测赛道)亚军(2/116队伍)。主持国家自然科学基金青年项目。

个人简介:
贾旭,大连理工大学未来技术学院/人工智能学院长聘副教授,辽宁省智能感知与理解人工智能重点实验室骨干成员,博士毕业于比利时鲁汶大学,师从Tinne Tuytelaars教授和Luc Van Gool教授,曾在Google Research,商汤科技,华为诺亚方舟实验室等从事研究工作。现主要研究方向包括视觉内容增强与生成、类脑视觉等,近年来在计算机视觉和机器学习领域顶级会议及期刊发表论文40余篇,Google Scholar引用8300余次,申请国内外专利10余项。主持或参与国家自然科学基金重点项目、科技部科技创新2030重大项目以及华为等多项科研项目。担任IJCAI、ICLR多个国际顶级会议和期刊的领域主席和审稿人,CCF、CSIG中多个专委会执委,及VALSE第六、七届执委。
论坛日程
时间:
2024年10月19日17:30-19:30
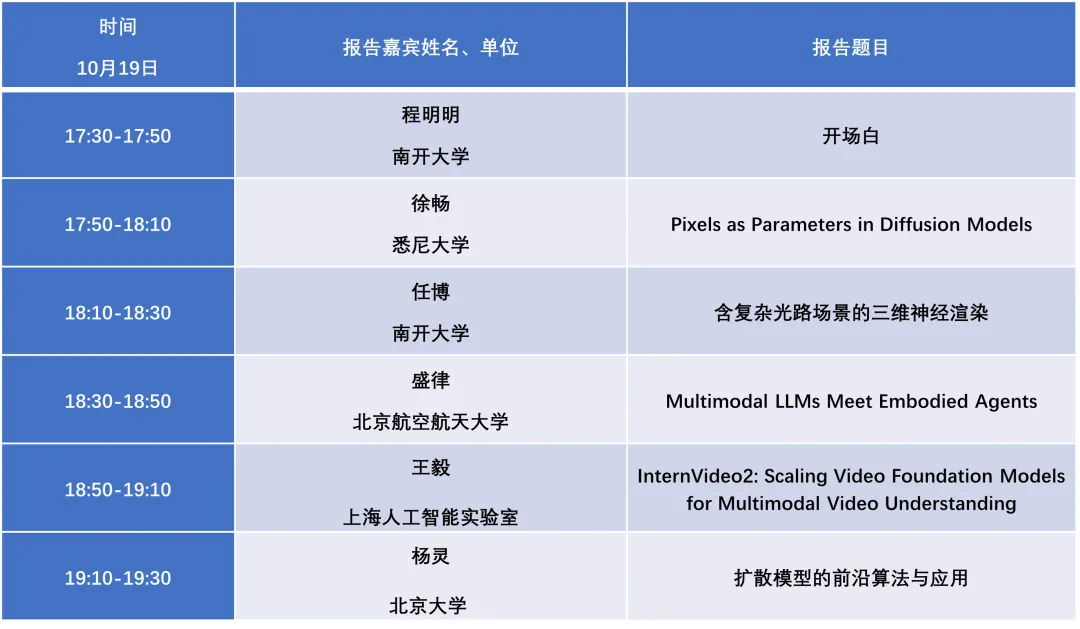
论坛报告

报告题目:
Pixels as Parameters in Diffusion Models(17:50-18:10)报告摘要:
个人简介:
徐畅,澳大利亚悉尼大学副教授,澳大利亚研究理事会杰出青年学者(ARC Future Fellow)。他的研究领域主要集中在机器学习算法及相关计算机视觉应用。他已在国际知名期刊和顶级学术会议上发表了超过200篇论文,并获得多项重要的学术奖项,包括2023年AAAI杰出论文奖,以及2018年IJCAI杰出论文奖。他在NeurIPS、ICML、ICLR和CVPR等知名会议担任领域主席,并在AAAI与IJCAI担任高级程序委员。此外,他还担任IEEE T-PAMI、IEEE T-MM和T-MLR的副主编。他荣获2023年度澳大利亚新南威尔士州州长优秀青年研究奖。

报告题目:
含复杂光路场景的三维神经渲染(18:10-18:30)报告摘要:
个人简介:
任博,南开大学计算机学院副教授。主要研究方向包括计算机图形学基于物理/机器学习的仿真与控制,神经辐射场三维场景重建与渲染等。在国际顶级期刊会议发表文章二十余篇。主持或参与多项国家自然科学基金青年/面上项目,国家重点研发计划课题。任中国图学学会理事会国际联络工作委员会,CCF CAD&CG专委会,CSIG智能图形专委会委员。在SIGGRAPH Asia,CVM,Pacific Graphics等图形学国际会议中出任分会场主席。

报告题目:
Multimodal LLMs Meet Embodied Agents(18:30-18:50)报告摘要:
报告人简介:
盛律,博导,北京航空航天大学“卓越百人”副教授,入选北航青年拔尖计划。主要研究方向为三维视觉和具身智能。在IEEE TPAMI/IJCV/TIP以及CVPR/ICCV/NeurIPS/ICLR/ECCV等重要国际期刊和会议发表论文超过50篇, Google Scholar显示被引用数超5000次。组织ICML 2024 Multimodal Foundation Models Meet Embodied AI和ICCV 2021 SenseHuman等多个国际会议研讨会。现任ACM Computing Surveys副编辑,CVPR 2024、ECCV 2024和ACM Multimedia 2024领域主席,以及多个领域顶会顶刊审稿人和程序委员。任CCF和CSIG多个专委会执行委员,VALSE执行领域主席。主持或参与多项国家自然科学基金、科技部重点研发计划和省部级重点研发计划项目。

报告题目:
报告摘要:
报告人简介:
王毅,于香港中文大学获得博士学位,专注于计算机视觉中的视频/图像理解和生成。他在顶级期刊和会议等发表20余篇论文,1篇论文曾入选CVPR2022 best paper finalist。他在多个期刊和会议上担任评审。他的研究工作获得了超过2500次引用。他曾获得9项国际比赛第一名,包括CVPR具身智能RxR-Habitat赛道冠军,ECCV第一视角视频5个赛道冠军等。成果包括通用视频大模型InternVideo、视频多模态数据集InternVid和首个视频对话系统VideoChat。

报告题目:
报告摘要:
报告人简介:
杨灵,北京大学博士在读,导师为崔斌教授,研究方向为扩散模型,多次获得北京大学国家奖学金、学术创新奖等,入选Valse 2024优秀学生论坛(全国一共8名学生)。主编AIGC专著《扩散模型:生成式AI模型的理论、应用与代码实践》,一作在CVPR/NeurIPS/ICML/ICLR/TKDE等顶刊顶会上共发表论文15篇,长期担任SIGGRAPH, TPAMI, ICML, ICLR, NeurIPS, CVPR等顶刊顶会审稿人,一作发表文生图SOTA框架RPG-DiffusionMaster,性能超越Stable Diffusion XL和OpenAI的DALL-E 3,和OpenAI合作一作发表全球首篇扩散模型综述。长期和OpenAI、斯坦福大学等知名研究机构在文生图/视频扩散模型等研究领域进行合作探索,一作文章总被引1300次。

